However, I argue that these strong metaprogramming features must be accompanied by strong "user experience" features. These UX features must provide transparency and convenience to a convention-breaking extent, for if they do not, metaprogramming may end up needlessly under-adopted.

Meta-programming has a best-case usage which is easy to envision. It prevents the drudgery and unreliability that comes with manual repetition. It reduces the number of keywords a language must reserve, and allows meta-code to replace potentially ambiguous spec. It enhances the democracy of mainstream languages, in that a programmer will be better able to develop a new programming paradigm, and make it easy to use, without having to perform boilerplate tool development or appeal to a language committee.
But metaprogramming has its detractors, and these detractors do not have these best-case scenarios in mind. Rather, many of them have years of experience dealing with the worst cases of metaprogramming. They object, correctly, that metaprogrammed procedures and datatypes are more difficult to read, debug, and interact with. I myself can say that I've avoided the use of libraries due to the amount of metaprogramming present. The old language was bad, and the new language is better, but the difficulty of reading and using remains.
It is only once these languages are out there that the true number of people who detest metaprogramming will become known. It may be a lot of people, one for every team in every company. Compound this with the fact that metaprogramming is useful only a bit more frequently than the (also controversial) templates and macros it is intended to replace, and it is likely that many teams will opt to abstain entirely from using metaprogramming in its new form. If you've ever worked in an office with a small number of vegetarians, you may know how rare it for lunch outings to take place at a steakhouse. In that same vein, for metaprogramming to lose traction, abstention does not need to favored by a lot of people, it need only be favored by a few. There is an onus, then, to make the presence of metaprogramming as painless as possible for the minority who would otherwise veto it. Far more important than making metaprogramming easy to use, is making metaprogramming easy to ignore.

Fortunately, if you look at some of the properties of compile-time metaprogramming and its most common use cases, a solution to this problem becomes clear. A metaprogram executes at build time, so to any non-meta-programmer, the only thing that matters about a metaprogram is its output. The output is instructive, because meta-code (like most code) is most easily understood through its inputs and outputs. Finally, metaprogram output does not change in response to a change in the non-meta-code.
Therefore, a multiparadigm metaprogrammable language ought to permit -- and facilitate the production of -- code which is simultaneously expressed as both meta-code and the meta-code's bullshit-free output. This way, people who do not metaprogram, but do make use of its output, can interact with the output in a way that is no different than if no metaprogramming ever took place. They can pretend metaprogramming simply does not exist.
Let's look at an example of this idea, and why it might make people happy. Here are two procedures and a use of them which constitutes a simple form of metaprogramming. In the interest of making the syntax as easy-to-understand as possible, I've written them in a fictional language.
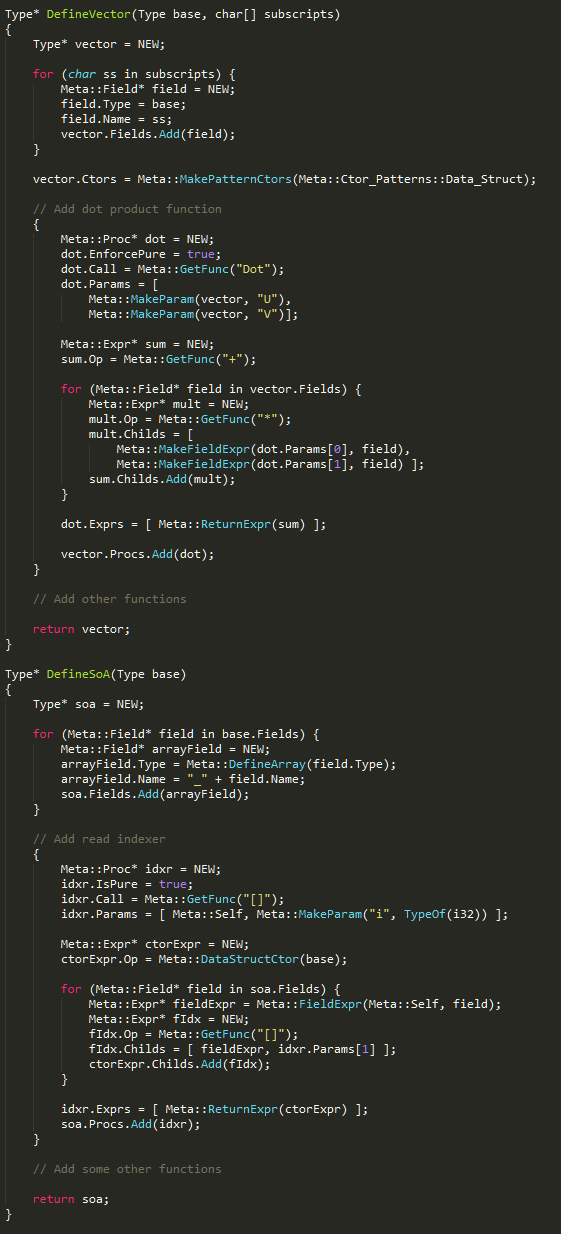
The @= expression tells the compiler to evaluate the assignment at compile time, creating a new type which works the same way as a type written in conventional code. The type serves to hold the pixels in an image. The type is a Structure-of-Arrays, the Structure-of-Arrays has been generated based on a Vector type, and the Vector type was defined to have float components with the names R, G, B, and A.
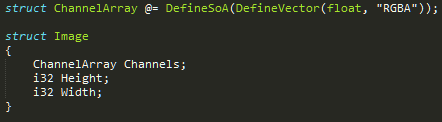
ChannelArray can be very easily understood by someone who is familiar with the concepts of an SoA and a mathematical vector. And on top of that, there may be a subgroup of programmers who easily understand it, simply because they read meta-code as easily as they read Dr Seuss. But what about the other people, who are familiar with neither SoA+Vector or metaprogramming, whom you want to have use this type? These people might navigate over to the definitions of MakeVector and MakeSoA, try for a second to parse them, and develop cold feet! And that's a shame because the Vector and SoA types which live inside of your binary are not particularly complicated.
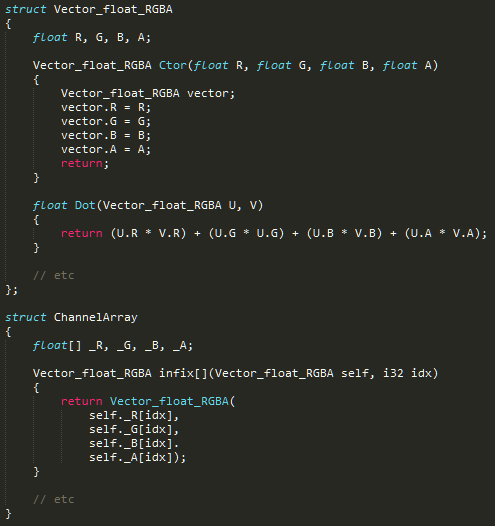
You don't even need to be particularly adverse to metaprogramming to wish that code existed in this form. This form of code can be read by a tenderfoot, stepped through with a debugger, and it will populate autocomplete databases on the simplest of text editors.
It might seem like I'm strawmanning here by having the meta-procedures take this particular form, and not using, for example, manipulation of source code strings or a special templating syntax. But these come with their own problems for metaprogramming opponents -- the latter requires a user to learn a syntax of domain-specific utility, and the former is terrifying to anyone whose job relies on code being secure. Should your language allow all three forms of type-generating functions, good for you, but now you've invited a new variety of belligerent, who tolerates metaprogramming but only via a particular method.
It may also seem like I'm being a jerk by precluding the possibility of tools. The body of ChannelArray could be output to a separate file, or maybe it could appear in a special debugger. Herb Sutter says as much in this clip of a CppCon talk he gave. He argues that C++ has always had abstractions which make code less readable, and relied on tools and education to counter-act this.
To this, a curmudgeon might say, "what if I don't want to use the damned tools?" This is a good point, and it's an even stronger point considering how far you can get without any metaprogramming at all. The attitude of "You Don't Need To See It" might not win out this time.
Solution time. I am in the privileged position of having done metaprogramming using an inelegant tool named Cog. Cog works via inline text generation: python code goes in a comment block, and the output of that python code gets output directly below the comment block, as part of a build step.

In many ways, Cog is a pain in the butt. The python code is not aware of or great at parsing any of the languages in my runtime code. Text editors often turn knot themselves up as I edit two languages in the same file, one of which dictates control flow with whitespace. To metaprogram requires string manipulation, a task at which python is not the best.
And yet! I have a deep love for Cog because I never have to worry that my hacky metaprogramming will be unreadable to other people, or that I'll have to manually extract the sane code out from between the gears of some build tool. If I share a file I wrote with cog's assistance, I like to leave the python code intact. Each python block serves as an explainer for the code below it, and a promise that the patterns present in the code are as consistent as silicon permits. I have had people work on my code who do not know python -- it's not a problem because they don't need to write or even read it. All they need to know are the two symbols to denote code that is generated. I consider inline text generation to be such a simple and powerful tool that I attempted a C# version of it, which I named "Whomst."
Languages like Jai and C++ do not need to mimic Cog's mechanism of action, but they should mimic Cog's user experience. For just as Cog supports metaprogramming via inline text generation, these languages can support comprehensibility via inline text generation. It could look something like this.
Before the first successful build:

After the first successful build:
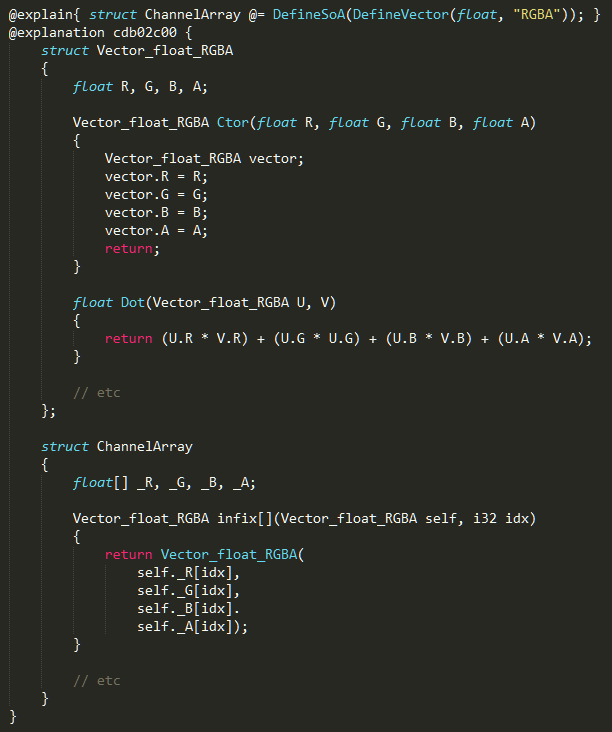
An optional "explain block" surrounds some piece of meta-code. Following a successful build, an "explanation block" is either inserted beneath it or modified. The contents of the first block gospel for the compiler, but a debug database might point to lines in the second block instead.
Because the two blocks are right next to each other, it's easy to connect input and output. In a way, it's like having this
right next to this
Lastly, the explanation block holds a hashcode, which the compiler uses to determine if the contents of the explanation block have been edited accidentally.
There are some other benefits. In addition to being able to delete the blocks and keep the meta-code, you can also keep only the output, thereby signifying that while this code was once the product of a metaprogram, it no longer is.

Isn't this nice? Isn't it nice to co-exist? I could even see this paradigm being extended to all sort of abstractions which are fun to write and miserable to read, like closures, mixins, and initializers.
There are thorny issues with this idea, of course. A metaprogrammed operation may not neatly correspond with a block of code. It may involve code which is closed source. The explain block may undershoot or overshoot the extent to which abstractions are unraveled. Should the explain block inline those inline procedures? Or copy every member of a base class? The nuances must be hashed out with consideration for the code-reader, and every bit of consideration for the reader is a good thing indeed.
The thorniest issue is that this means that the compiler can modify source. It is an extreme change. But I believe it's necessitated by an extreme change in the way people code.
One more issue. I imagine a few of the people who are very comfortable with abstractions are now holding up their middle fingers to me, to show where they will hurt from the extra scrolling. I propose that they suffer for the short term, and here's the reason. This explain system will allow the ignorant to see metaprogramming's fruits right in front of their face. Over time these people will grow jealous and decide to learn to use metaprogramming themselves. Then metaprogramming will at last have widespread acceptance, a Reddit comment section battle will end, and we'll all hold hands and sing. That's my hunch, anyway.
(EDIT: read top comment)
Thank you for reading! This will my last bit of side work for a quite a while, but as usual, you can follow me here or on twitter, for updates on my main project, Swedish Cubes for Unity.